Ergebnisse
Ergebnisse und Fazit
Ergebnisse
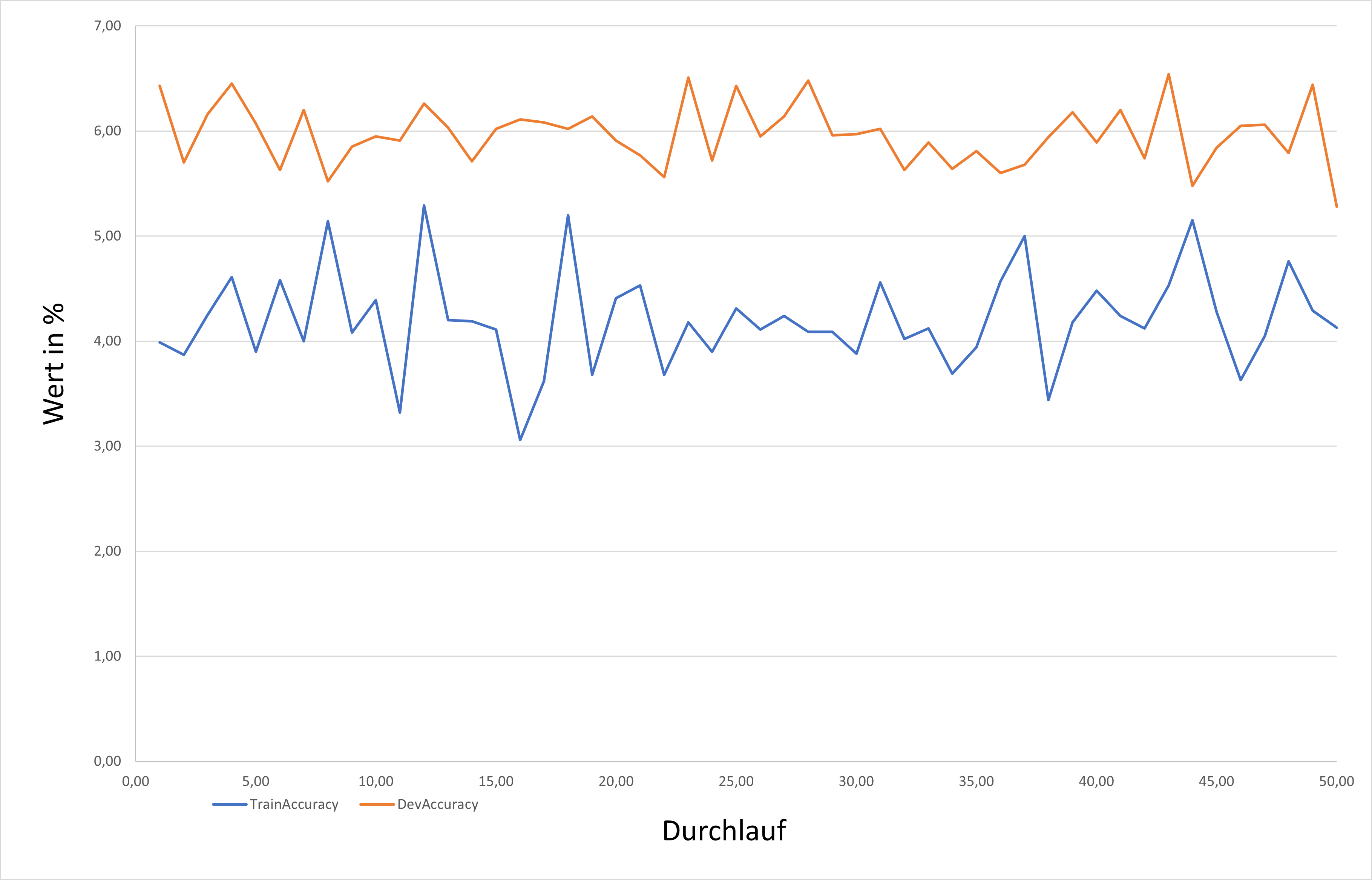
Am Ende jeder Epoche des Trainingsprogramms gibt der syntaktische Parser einen Wert mit der Genauigkeit des neuronalen Netzes aus. Letztendlich hat der Parser im Training nur einen Genauigkeitswert von 5.28 in den Developmentdaten mit 50 Epochen und einer Begrenzung jeder Epoche auf 100 Sätze erreicht. Dieser Wert lässt sich erhöhen, indem jede Epoche mit den vollen Trainings- und Developmentdaten trainiert.
| Genauigkeit | |
|---|---|
| Trainingsdaten | 4.13 |
| Developmentdaten | 5.28 |
Diagramm mit Development- und Trainingsgenauigkeit über 50 Epochen und 100 Sätzen pro Epoche:
Schwierigkeit:
- Hohe Laufzeit des Programms bei vollem Datensatz
- Durchmischen der Daten nach jeder Epoche, sodass immer wieder andere Daten vorliegen.
Verbesserung:
- kompletter Datensatz
- mehr Sätze in einer Epoche
- GPU-unterstütztes Gerät
- 250 Sätze pro Epoche, 50 Epochen:
| Genauigkeit | |
|---|---|
| Trainingsdaten | 4.70 |
| Developmentdaten | 5.52 |
Fazit
Neuronale Netze sollten weiterhin in Bezug auf historische Sprachen beobachtet werden, da mit solch einem Parser mit einem guten Modell sehr große Mengen an Text annotiert werden könnten. Trotzdem wäre es aber denkbar ein Korpus des Mittelhochdeutschen erst semi-automatisch mit syntaktischen Annotationen zu versehen, sodass diese korrigiert sind, und in einem zweiten Schritt einen Parser mit diesen Daten zu trainieren. Mit einem guten Modell und der Anwendung auf vielen Daten, wie die des Mittelhochdeutschen Wörterbuchs, könnten neue Erkenntnisse zu syntaktischen Phänomenen erkennbar werden und die Arbeit des Mittelhochdeutschen Wörterbuchs extrem erleichtern.