Implementierung
Der syntaktische Parser für das Mittelhochdeutsche wurde mit neuronalen Netzen und bidirektionalen LSTMs auf der Basis von Python 3 und PyTorch implementiert.
Schritte
Vorverarbeitung der Daten
Zum Training des syntaktischen Parsers wird ein schon syntaktisch annotiertes Set an Trainings- und Developmentdaten benötigt. Die Trainingsdaten machen beim maschinellen Lernen üblicherweise ca. 80-90% der vollen Daten aus.
Datenbasis:
- Die Baumbank Mittelhochdeutsch stellt derzeit die einzige umfangreiche syntaktisch annotierte Baumbank für das Mittelhochdeutsche dar.
- Fast alle Texte des Referenzkorpus Mittelhochdeutsch vollautomatisch annotiert von Chiarcos et al. (2018) mit dem QuantQualParser
- TSV-basiertes CoNLL-RDF
Prozess:
- CoNLL => TSV
- Korrigieren der Developmentdaten: : M001-M102
- Extraktion der syntaktischen Annotation
- Umwandlung zu TXT-Format und Bereinigung (Sätze zeilenweise, Sonderzeichen, Leerzeichen)
Vorverarbeitung: Text M015-N1_12-1_P als TSV | Text M015-N1_12-1_P bereinigt als TXT
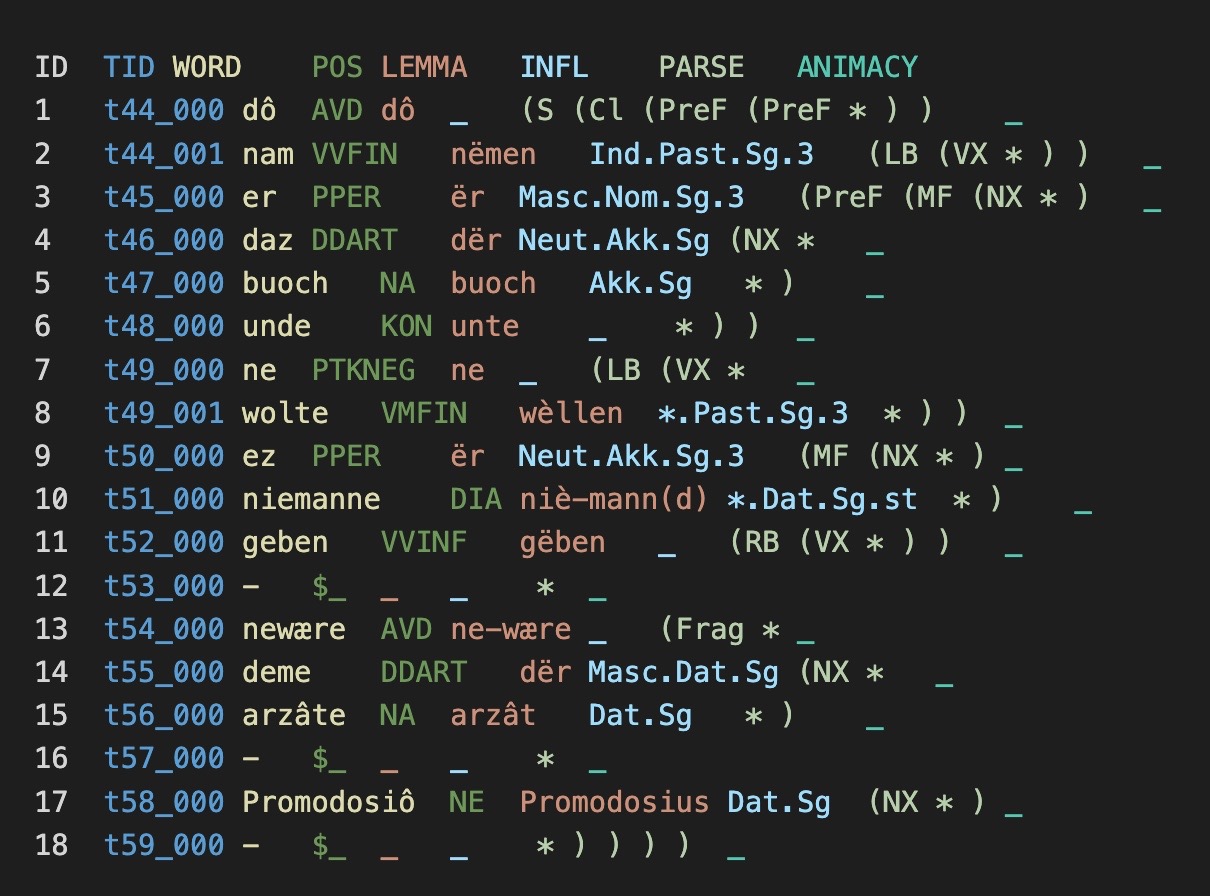
Einlesen der Daten
Zur Verarbeitung in einem neuronalen Netzwerk sollen die mittelhochdeutschen Texte in zwei Listen satzweise gespeichert werden:
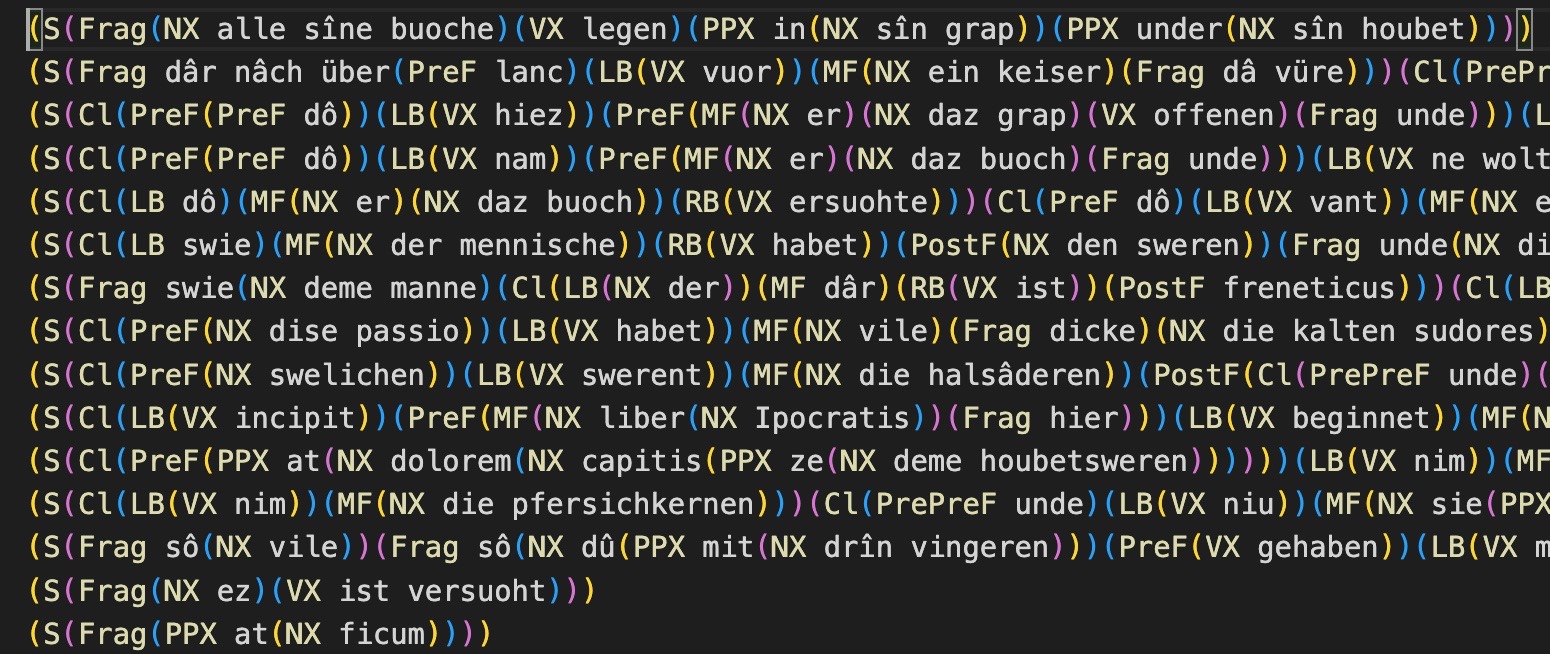
- Beispielteilsatz:
(S(Cl(PreF(NX man))(LB(VX gienc))(PPX after(NX wege)))) - alle Wörter:
['man', 'gienc', 'after', 'wege'] - alle Konstituenten mit Start- und Endpositionen:
[('S Cl', 0, 4), ('PreF NX', 0, 1), ('LB VX', 1, 2), ('PPX', 2, 4), ('NX', 3, 4)]
Damit sie als Tensor eingelesen werden können, wird jedes Wort mit buchstabenbasierten IDs ersetzt und es werden Suffixe und Präfixe jedes Wortes mit einer festen Länge von 10 Buchstaben abgespeichert. Kürzere Wörter werden mit Ersatz-IDs aufgefüllt. Dies hat sich schon im RNNTagger (Schmid 2017) als sinnvoll erwiesen.
Konvertierung der Wortlisten in einen numerischen Vektor:
def words2charIDvec(self, words):
""" converts a sequence of words to a suffix letter matrix
and a prefix letter matrix """
fwd_charID_seqs = []
bwd_charID_seqs = []
for word in words:
fwd_charIDs, bwd_charIDs = self._get_charIDs(word)
fwd_charID_seqs.append(fwd_charIDs)
bwd_charID_seqs.append(bwd_charIDs)
fwd_charID_seqs = numpy.asarray(fwd_charID_seqs, dtype='int32')
bwd_charID_seqs = numpy.asarray(bwd_charID_seqs, dtype='int32')
return fwd_charID_seqs, bwd_charID_seqs
Neuronales Netzwerk aufbauen
Das neuronale Netzwerk berechnet die Bewertungen jeder syntaktischen Kategorie eines Spans und verarbeitet die Wortrepräsentationen, sowie aus den Wortrepräsentationen die Spanrepräsentationen. Zur Berechnung der Spanrepräsentationen werden die Differenzvektoren der Vorwärts- und Rückwärtsrepräsentation der jeweiligen Start- und Endpositionen eines Spans nach dem Vorbild von Gaddy et al. (2018) konkateniert. Die Wort- und die Spanrepräsentationen werden jeweils mit einem bidirektionalen LSTM verarbeitet, sodass der Kontext eines Spans berücksichtigt werden kann. Nach und vor jedem LSTM wurde Dropout von 0.5 als Regularisierung angewandt.
Berechnung der Spanrepräsentation:
# run the BiLSTM over words
word_reprs = self.word_rnn(word_reprs.unsqueeze(0)).squeeze(0)
# Forward and backward sequence of word representations
forward = word_reprs
backward = word_reprs.flip(1)
# run the biLSTM over word_representations
fwd_outputs, _ = self.fwd_rnn(forward)
bwd_outputs, _ = self.bwd_rnn(backward)
# Forward and backward end and start positions
startposition_fwd = torch.split(fwd_outputs,int(self.char_rec_size/2),dim=1)[0]
startposition_bwd = torch.split(bwd_outputs,int(self.char_rec_size/2),dim=1)[0]
endposition_fwd = torch.split(fwd_outputs,int(self.char_rec_size/2),dim=1)[1]
endposition_bwd = torch.split(bwd_outputs,int(self.char_rec_size/2),dim=1)[1]
# concatenate the forward and backward final states to form
# span representations
forward = (endposition_fwd-startposition_fwd)
backward = (startposition_bwd - endposition_bwd)
# concatenate to build span representation
span_reprs = torch.cat((forward, backward),-1)
return span_reprs
Ausgabe der Bewertung über Pytorch-Linear-Funktion und ReLU
def forward(self, fwd_charIDs, bwd_charIDs, num_labels):
# compute the span representations
span_reprs = self.span_representations(fwd_charIDs, bwd_charIDs)
# apply dropout
span_reprs = self.dropout(span_reprs)
# output (Linear and ReLU)
self.linear = nn.Linear(self.word_rec_size, num_labels)
self.output_layer = nn.ReLU()
# apply the output layers
scores = self.output_layer(self.linear(span_reprs.unsqueeze(0))).squeeze(0)
return scores
Aufbau des neuronalen Netzes:
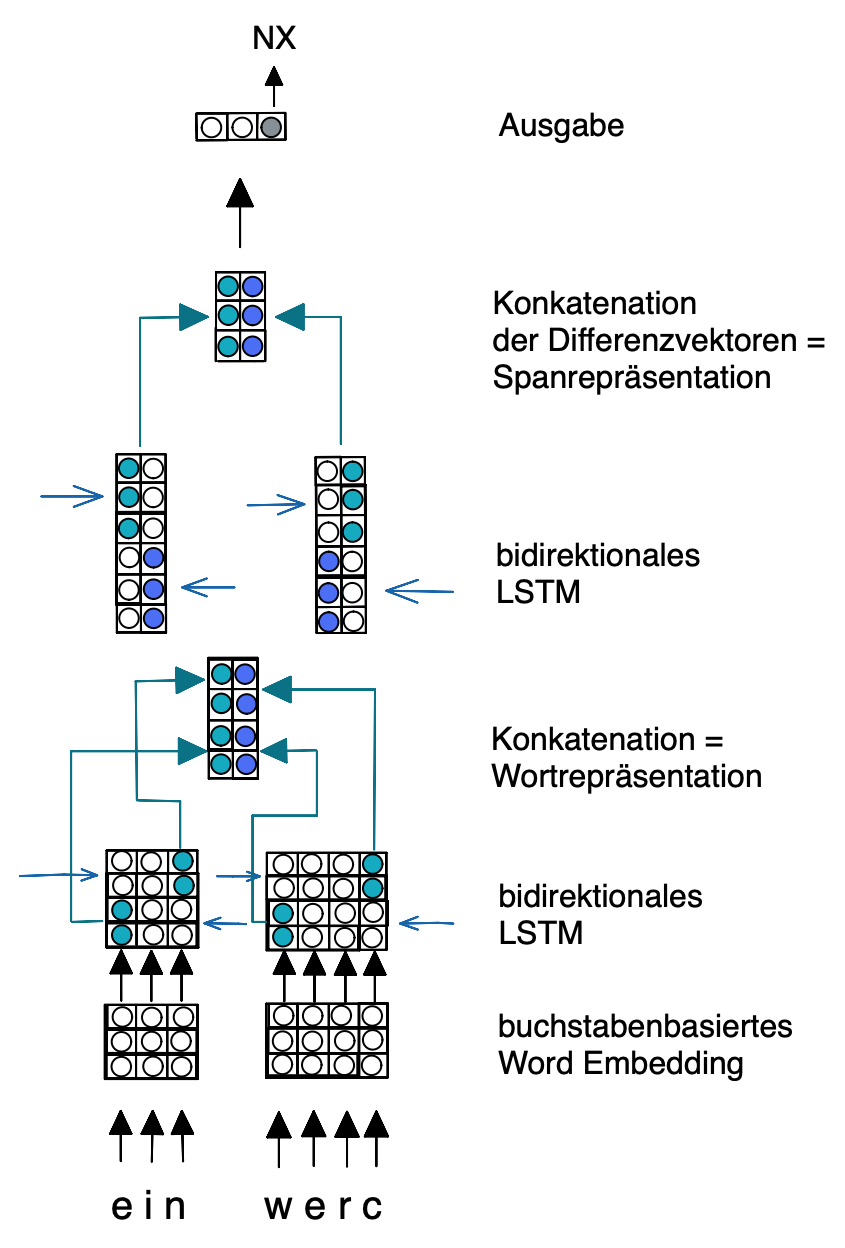
Training
Die neuronalen Netze werden über das Trainingsset (M104-M544) und das Developmentset (M001-M102) trainiert. Dabei werden über die Cross-Entropy-Loss-Funktion die besten Bewertungen immer wieder abgespeichert und anhand der Developmentdaten überprüft. Dazu wird über jeden einzelnen Span der eingegebenen Daten iteriert und dieser in das neuronale Netzwerk eingegeben.
Zur Berechnung des Verlusts wird für jeden Span ein Vektor mit den LabelIDs erstellt. Dieser Vorgang wird über 50 Batches wiederholt und ist aufgrund der hohen Laufzeit auf 250 Sätze beschränkt worden.
Training jedes Spans:
for iteration, (words, labels) in enumerate(sentences):
for span_no in range(len(labels)):
for label in labels:
start = label[1]
end = label[2]
constituent_len = end - start
if constituent_len >= 1:
label_vector = torch.zeros(constituent_len,len(labels))
fwd_charIDs, bwd_charIDs = data.words2charIDvec(words[start:end])
fwd_charIDs = model.long_tensor(fwd_charIDs)
bwd_charIDs = model.long_tensor(bwd_charIDs)
if constituent_len >= 2:
label_tview = label_vector.view(constituent_len, len(labels))
label_tview[end - start - constituent_len][span_no] = data.labelID(label)
else:
label_tview = label_vector.view(constituent_len,len(labels))
label_tview[end - start -1][span_no] = data.labelID(label)
# run the model
if type(model) is Parser:
labelscores = model(fwd_charIDs, bwd_charIDs, len(labels))
#print("Labelvector: ")
#print(label_tview.squeeze(0))
loss = loss_function(labelscores, label_tview)
# compute the label predictions
_, predicted_labelIDs = labelscores.max(-1)
_, pre_label_tview = label_tview.max(-1)
Abspeichern des Netzwerks und der Parameterdatei, Shuffle der Daten nach jeder Epoche:
for epoch in range(args.epochs):
random.shuffle(data.train_parses) # data is shuffled after each epoch
loss, accuracy = run_parser(data.train_parses, data, model, optimizer)
print("Epoch:", epoch+1, file=sys.stderr)
print("TrainLoss: %.0f" % loss, "TrainAccuracy: %.2f" % accuracy, file=sys.stderr)
sys.stderr.flush();
if epoch >= args.burn_in_epochs:
scheduler.step()
loss, accuracy = run_parser(data.dev_parses, data, model)
print(epoch+1, "DevLoss: %.0f" % loss, "DevAccuracy: %.2f" % accuracy)
sys.stdout.flush()
### keep the model which performs best on dev data
if max_accuracy < accuracy:
max_accuracy = accuracy
with open(args.path_param+".hyper", "wb") as file:
pickle.dump(hyper_params, file)
if model.on_gpu():
model = model.cpu()
torch.save(model.state_dict(), args.path_param+".rnn")
model = model.cuda()
else:
torch.save(model.state_dict(), args.path_param+".rnn")
Anwendung
Die Anwendung des Parser erfolgt über ein kommandobasiertes Shellskript, welches die Pythondatei aufruft. Dazu müssen textbasierte mittelhochdeutsche Texte mit zeilenweiser Satztokenisierung als Eingabe und der gewünschte Ausgabepfad angegeben werden.
Zur Berechnung der syntaktischen Kategorien des Eingabetextes wird mithilfe des trainierten neuronalen Netzes und dem Viterbi-Algorithmus jeweils die beste Zerlegung aller möglichen Spans und die beste syntaktische Kategoeir berechnet. der best-bewertetste Parsebaum wird dann ausgegeben.
Berechnung der besten Bewertung und der besten Kategorie über Viterbi-Algorithmus:
def parse(sentences, data, model):
for i, words in enumerate(sentences):
# for all constituents
for constituent_len in range(1,len(words)-1):
# for all startpositions
for start in range(len(words)-constituent_len):
# end position
end = start+constituent_len
for label in data.ID2label:
if constituent_len == 1:
fwd_charIDs, bwd_charIDs = data.words2charIDvec(words[start:end])
fwd_charIDs = model.long_tensor(fwd_charIDs)
bwd_charIDs = model.long_tensor(bwd_charIDs)
# Score of category
labelscores = model(fwd_charIDs, bwd_charIDs, len(words)-constituent_len)
# best category
_, labelID = labelscores.max(dim=-1)
best_label = torch.argmax(labelID)
best_label = data.ID2label(label)
else:
left_encodings = []
right_encodings = []
for split in range(start + 1, end):
# get split scores
left_fwd_charIDs, left_bwd_charIDs = data.words2charIDvec(words[start:split])
left_fwd_charIDs = model.long_tensor(left_fwd_charIDs)
left_bwd_charIDs = model.long_tensor(left_bwd_charIDs)
left_scores = model(left_fwd_charIDs, left_bwd_charIDs, len(words)-constituent_len)
left_encodings.append(left_scores)
right_fwd_charIDs, right_bwd_charIDs = data.words2charIDvec(words[split:end])
right_fwd_charIDs = model.long_tensor(right_fwd_charIDs)
right_bwd_charIDs = model.long_tensor(right_bwd_charIDs)
right_scores = model(right_fwd_charIDs, right_bwd_charIDs, len(words)-constituent_len)
right_encodings.append(right_scores)
_, labelID = left_scores.max(dim=-1)
#Label of splitted constituents
best_label = torch.argmax(labelID)
best_label = data.ID2label(best_label)
_, labelID_right = right_scores.max(dim=-1)
label_right = torch.argmax(labelID_right)
label_right = data.ID2label(label_right)
split_score=torch.argmax(left_encodings+right_encodings)
# Beste Zerlegung
return build_parse(start, end, best_label, words, split_score)
Parser herunterladen
Der syntaktische Parser für das Mittelhochdeutsche kann hier heruntergeladen werden.